Note
Go to the end to download the full example code.
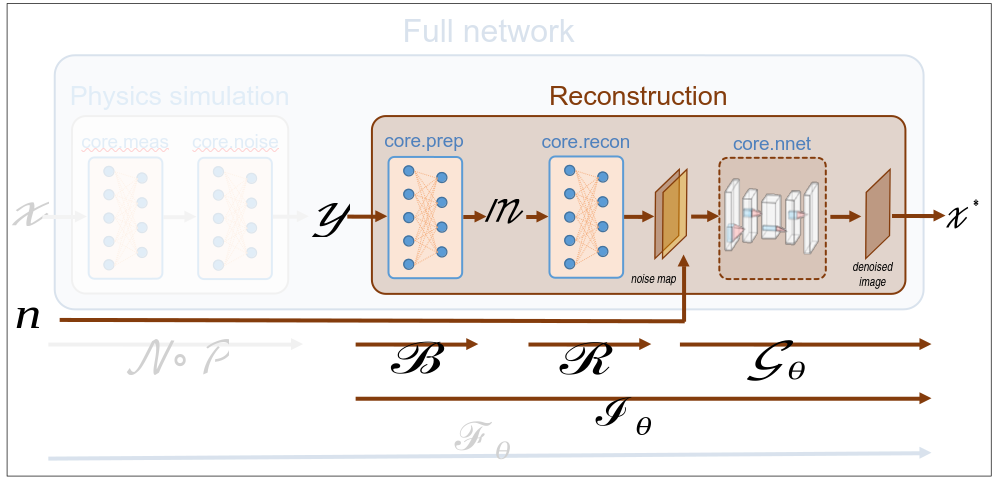
07. DCNet with plug-and-play DRUNet denoising
This tutorial shows how to perform image reconstruction using a DCNet (data completion network) that includes a DRUNet denoiser. DRUNet is a pretrained plug-and-play denoising network that has been pretrained for a wide range of noise levels. DRUNet admits the noise level as an input. Contratry to the DCNet described in Tutorial 6, it requires no training.
Note
As in the previous tutorials, we consider a split Hadamard operator and measurements corrupted by Poisson noise (see Tutorial 5).
import numpy as np
import os
from spyrit.misc.disp import imagesc
import matplotlib.pyplot as plt
Load a batch of images
Images \(x\) for training neural networks expect values in [-1,1]. The images are normalized using the transform_gray_norm() function.
# sphinx_gallery_thumbnail_path = 'fig/drunet.png'
from spyrit.misc.statistics import transform_gray_norm
import torchvision
import torch
h = 64 # image size hxh
i = 1 # Image index (modify to change the image)
spyritPath = os.getcwd()
imgs_path = os.path.join(spyritPath, "images")
# Create a transform for natural images to normalized grayscale image tensors
transform = transform_gray_norm(img_size=h)
# Create dataset and loader (expects class folder 'images/test/')
dataset = torchvision.datasets.ImageFolder(root=imgs_path, transform=transform)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=7)
x, _ = next(iter(dataloader))
print(f"Shape of input images: {x.shape}")
# Select image
x = x[i : i + 1, :, :, :]
x = x.detach().clone()
b, c, h, w = x.shape
# plot
x_plot = x.view(-1, h, h).cpu().numpy()
imagesc(x_plot[0, :, :], r"$x$ in [-1, 1]")
![$x$ in [-1, 1]](../_images/sphx_glr_tuto_07_drunet_split_measurements_001.png)
Shape of input images: torch.Size([7, 1, 64, 64])
Operators for split measurements
We consider noisy measurements obtained from a split Hadamard operator, and a subsampling strategy that retaines the coefficients with the largest variance (for more details, refer to Tutorial 5).
First, we download the covariance matrix from our warehouse.
import girder_client
# api Rest url of the warehouse
url = "https://pilot-warehouse.creatis.insa-lyon.fr/api/v1"
# Generate the warehouse client
gc = girder_client.GirderClient(apiUrl=url)
# Download the covariance matrix and mean image
data_folder = "./stat/"
dataId_list = [
"63935b624d15dd536f0484a5", # for reconstruction (imageNet, 64)
"63935a224d15dd536f048496", # for reconstruction (imageNet, 64)
]
cov_name = "./stat/Cov_64x64.npy"
try:
for dataId in dataId_list:
myfile = gc.getFile(dataId)
gc.downloadFile(dataId, data_folder + myfile["name"])
print(f"Created {data_folder}")
Cov = np.load(cov_name)
print(f"Cov matrix {cov_name} loaded")
except:
Cov = np.eye(h * h)
print(f"Cov matrix {cov_name} not found! Set to the identity")
Created ./stat/
Cov matrix ./stat/Cov_64x64.npy loaded
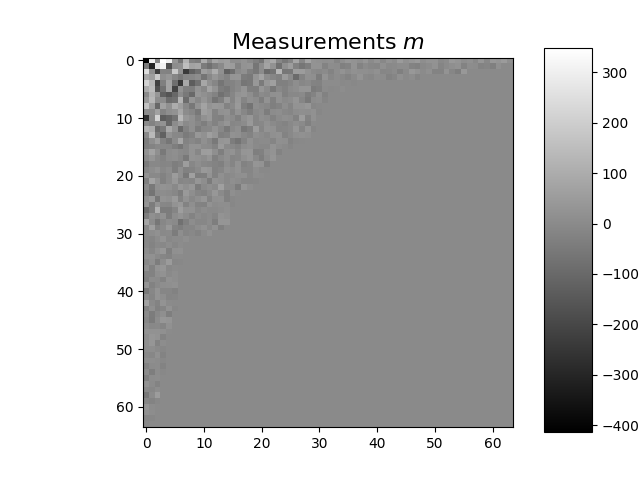
We define the measurement, noise and preprocessing operators and then simulate a measurement vector corrupted by Poisson noise. As in the previous tutorials, we simulate an accelerated acquisition by subsampling the measurement matrix by retaining only the first rows of a Hadamard matrix that is permuted looking at the diagonal of the covariance matrix.
from spyrit.core.meas import HadamSplit
from spyrit.core.noise import Poisson
from spyrit.misc.sampling import meas2img
from spyrit.misc.statistics import Cov2Var
from spyrit.core.prep import SplitPoisson
# Measurement parameters
M = 64 * 64 // 4 # Number of measurements (here, 1/4 of the pixels)
alpha = 100.0 # number of photons
# Measurement and noise operators
Ord = Cov2Var(Cov)
meas_op = HadamSplit(M, h, torch.from_numpy(Ord))
noise_op = Poisson(meas_op, alpha)
prep_op = SplitPoisson(alpha, meas_op)
# Vectorize image
x = x.view(b * c, h * w)
print(f"Shape of vectorized image: {x.shape}")
# Measurements
y = noise_op(x) # a noisy measurement vector
m = prep_op(y) # preprocessed measurement vector
m_plot = m.detach().numpy()
m_plot = meas2img(m_plot, Ord)
imagesc(m_plot[0, :, :], r"Measurements $m$")
Shape of vectorized image: torch.Size([1, 4096])
DRUNet denoising
DRUNet is defined by the spyrit.external.drunet.DRUNet class. This class inherits from the original spyrit.external.drunet.UNetRes class introduced in [ZhLZ21], with some modifications to handle different noise levels.
We instantiate the DRUNet by providing the noise level, which is expected to be in [0, 255], and the number of channels. The larger the noise level, the higher the denoising.
from spyrit.external.drunet import DRUNet
noise_level = 7
denoi_drunet = DRUNet(noise_level=noise_level, n_channels=1)
# Use GPU, if available
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
denoi_drunet = denoi_drunet.to(device)
We download the pretrained weights of the DRUNet and load them.
try:
import gdown
# Download pretrained weights
model_drunet_path = "./model"
url_drunet = "https://drive.google.com/file/d/1fhnIDJAbh7IRSZ9tgk4JPtfGra4O1ghk/view?usp=drive_link"
if os.path.exists(model_drunet_path) is False:
os.mkdir(model_drunet_path)
print(f"Created {model_drunet_path}")
model_drunet_path = os.path.join(model_drunet_path, "drunet_gray.pth")
gdown.download(url_drunet, model_drunet_path, quiet=False, fuzzy=True)
# Load pretrained weights
denoi_drunet.load_state_dict(torch.load(model_drunet_path), strict=False)
print(f"Model {denoi_drunet} loaded.")
except:
print(f"Model {model_drunet_path} not found!")
Downloading...
From: https://drive.google.com/uc?id=1fhnIDJAbh7IRSZ9tgk4JPtfGra4O1ghk
To: /home/docs/checkouts/readthedocs.org/user_builds/spyrit/checkouts/2.3.1/tutorial/model/drunet_gray.pth
0%| | 0.00/131M [00:00<?, ?B/s]
4%|▎ | 4.72M/131M [00:00<00:04, 25.4MB/s]
7%|▋ | 8.91M/131M [00:00<00:04, 26.0MB/s]
13%|█▎ | 17.3M/131M [00:00<00:04, 27.0MB/s]
20%|█▉ | 25.7M/131M [00:00<00:04, 25.9MB/s]
26%|██▌ | 34.1M/131M [00:01<00:03, 29.1MB/s]
30%|███ | 39.3M/131M [00:01<00:02, 32.7MB/s]
33%|███▎ | 43.0M/131M [00:01<00:02, 30.1MB/s]
36%|███▌ | 46.7M/131M [00:01<00:03, 27.4MB/s]
42%|████▏ | 54.5M/131M [00:01<00:02, 37.1MB/s]
45%|████▌ | 59.2M/131M [00:02<00:02, 26.2MB/s]
52%|█████▏ | 67.6M/131M [00:02<00:02, 26.2MB/s]
58%|█████▊ | 76.0M/131M [00:02<00:02, 24.8MB/s]
65%|██████▍ | 84.4M/131M [00:03<00:01, 25.9MB/s]
71%|███████ | 92.8M/131M [00:03<00:01, 26.7MB/s]
77%|███████▋ | 101M/131M [00:03<00:01, 27.3MB/s]
81%|████████ | 106M/131M [00:03<00:00, 29.7MB/s]
84%|████████▍ | 110M/131M [00:03<00:00, 27.0MB/s]
90%|█████████ | 118M/131M [00:04<00:00, 28.1MB/s]
100%|██████████| 131M/131M [00:04<00:00, 30.2MB/s]
Model DRUNet(
(m_head): Conv2d(2, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(m_down1): Sequential(
(0): ResBlock(
(res): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(1): ResBlock(
(res): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(2): ResBlock(
(res): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(3): ResBlock(
(res): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(4): Conv2d(64, 128, kernel_size=(2, 2), stride=(2, 2), bias=False)
)
(m_down2): Sequential(
(0): ResBlock(
(res): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(1): ResBlock(
(res): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(2): ResBlock(
(res): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(3): ResBlock(
(res): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(4): Conv2d(128, 256, kernel_size=(2, 2), stride=(2, 2), bias=False)
)
(m_down3): Sequential(
(0): ResBlock(
(res): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(1): ResBlock(
(res): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(2): ResBlock(
(res): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(3): ResBlock(
(res): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(4): Conv2d(256, 512, kernel_size=(2, 2), stride=(2, 2), bias=False)
)
(m_body): Sequential(
(0): ResBlock(
(res): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(1): ResBlock(
(res): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(2): ResBlock(
(res): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(3): ResBlock(
(res): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
)
(m_up3): Sequential(
(0): ConvTranspose2d(512, 256, kernel_size=(2, 2), stride=(2, 2), bias=False)
(1): ResBlock(
(res): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(2): ResBlock(
(res): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(3): ResBlock(
(res): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(4): ResBlock(
(res): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
)
(m_up2): Sequential(
(0): ConvTranspose2d(256, 128, kernel_size=(2, 2), stride=(2, 2), bias=False)
(1): ResBlock(
(res): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(2): ResBlock(
(res): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(3): ResBlock(
(res): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(4): ResBlock(
(res): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
)
(m_up1): Sequential(
(0): ConvTranspose2d(128, 64, kernel_size=(2, 2), stride=(2, 2), bias=False)
(1): ResBlock(
(res): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(2): ResBlock(
(res): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(3): ResBlock(
(res): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(4): ResBlock(
(res): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
)
(m_tail): Conv2d(64, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
) loaded.
Pluggind the DRUnet in a DCNet
We define the DCNet network by providing the forward operator, preprocessing operator, covariance prior and denoising prior. The DCNet class spyrit.core.recon.DCNet is discussed in Tutorial 06.
from spyrit.core.recon import DCNet
dcnet_drunet = DCNet(noise_op, prep_op, torch.from_numpy(Cov), denoi=denoi_drunet)
dcnet_drunet = dcnet_drunet.to(device) # Use GPU, if available
Then, we reconstruct the image from the noisy measurements.
with torch.no_grad():
z_dcnet_drunet = dcnet_drunet.reconstruct(y.to(device))
Tunning of the denoising
We reconstruct the images for another two different noise levels of DRUnet
noise_level_2 = 1
noise_level_3 = 20
with torch.no_grad():
denoi_drunet.set_noise_level(noise_level_2)
z_dcnet_drunet_2 = dcnet_drunet.reconstruct(y.to(device))
denoi_drunet.set_noise_level(noise_level_3)
z_dcnet_drunet_3 = dcnet_drunet.reconstruct(y.to(device))
Plot all reconstructions
from spyrit.misc.disp import add_colorbar, noaxis
x_plot = z_dcnet_drunet.view(-1, h, h).cpu().numpy()
x_plot2 = z_dcnet_drunet_2.view(-1, h, h).cpu().numpy()
x_plot3 = z_dcnet_drunet_3.view(-1, h, h).cpu().numpy()
f, axs = plt.subplots(1, 3, figsize=(10, 5))
im1 = axs[0].imshow(x_plot2[0, :, :], cmap="gray")
axs[0].set_title(f"DRUNet\n (n map={noise_level_2})", fontsize=16)
noaxis(axs[0])
add_colorbar(im1, "bottom")
im2 = axs[1].imshow(x_plot[0, :, :], cmap="gray")
axs[1].set_title(f"DRUNet\n (n map={noise_level})", fontsize=16)
noaxis(axs[1])
add_colorbar(im2, "bottom")
im3 = axs[2].imshow(x_plot3[0, :, :], cmap="gray")
axs[2].set_title(f"DRUNet\n (n map={noise_level_3})", fontsize=16)
noaxis(axs[2])
add_colorbar(im3, "bottom")

<matplotlib.colorbar.Colorbar object at 0x7f8c6b051b50>
Alternative implementation showing the advantage of the DRUNet class
First, we consider DCNet without denoising in the image domain (default behaviour)
Then, we instantiate DRUNet using the original class spyrit.external.drunet.UNetRes.
from spyrit.external.drunet import UNetRes as drunet
# Define denoising network
n_channels = 1 # 1 for grayscale image
drunet_den = drunet(in_nc=n_channels + 1, out_nc=n_channels)
# Load pretrained model
try:
drunet_den.load_state_dict(torch.load(model_drunet_path), strict=True)
print(f"Model {model_drunet_path} loaded.")
except:
print(f"Model {model_drunet_path} not found!")
load_drunet = False
drunet_den = drunet_den.to(device)
Model ./model/drunet_gray.pth loaded.
To denoise the output of DCNet, we create noise-level map that we concatenate to the output of DCNet that we normalize in [0,1]
x_sample = 0.5 * (z_dcnet + 1).cpu()
#
x_sample = torch.cat(
(
x_sample,
torch.FloatTensor([noise_level / 255.0]).repeat(
1, 1, x_sample.shape[2], x_sample.shape[3]
),
),
dim=1,
)
x_sample = x_sample.to(device)
with torch.no_grad():
z_dcnet_den = drunet_den(x_sample)
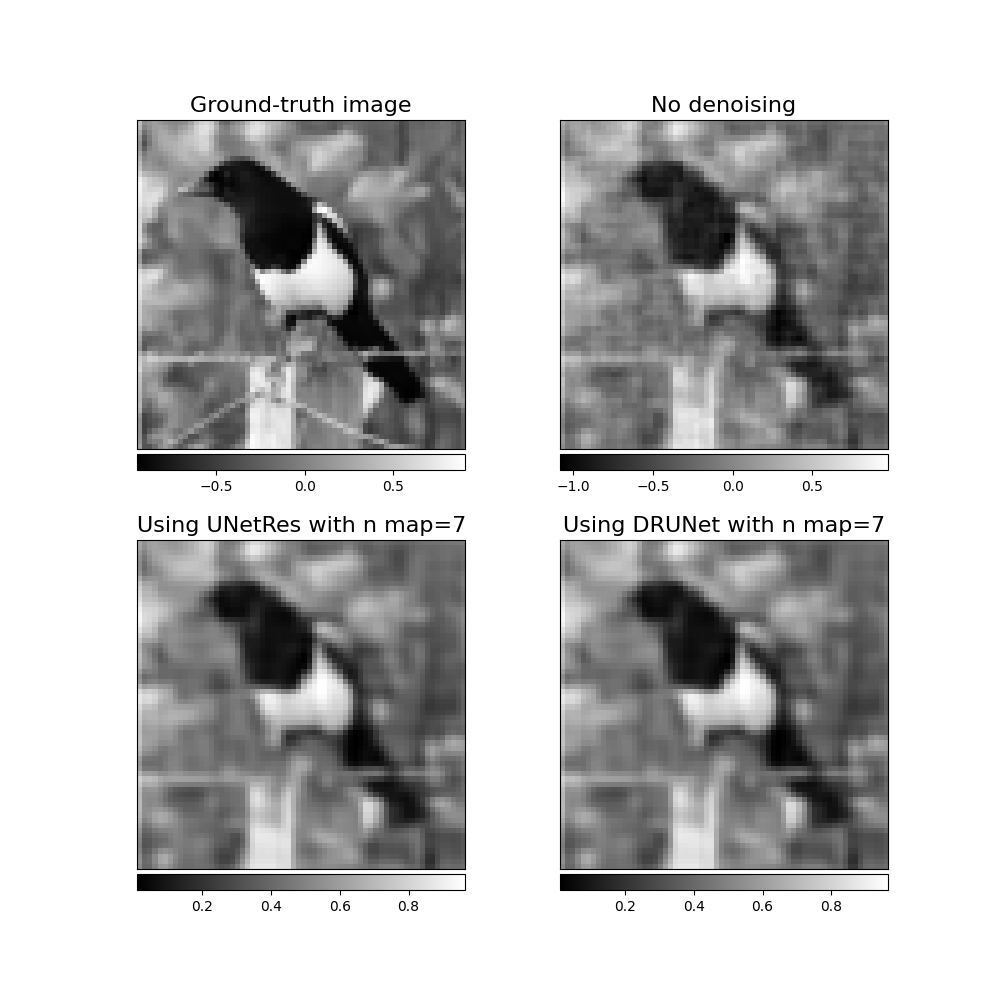
We plot all results
x_plot = x.view(-1, h, h).cpu().numpy()
x_plot2 = z_dcnet.view(-1, h, h).cpu().numpy()
x_plot3 = z_dcnet_drunet.view(-1, h, h).cpu().numpy()
x_plot4 = z_dcnet_den.view(-1, h, h).cpu().numpy()
f, axs = plt.subplots(2, 2, figsize=(10, 10))
im1 = axs[0, 0].imshow(x_plot[0, :, :], cmap="gray")
axs[0, 0].set_title("Ground-truth image", fontsize=16)
noaxis(axs[0, 0])
add_colorbar(im1, "bottom")
im2 = axs[0, 1].imshow(x_plot2[0, :, :], cmap="gray")
axs[0, 1].set_title("No denoising", fontsize=16)
noaxis(axs[0, 1])
add_colorbar(im2, "bottom")
im3 = axs[1, 0].imshow(x_plot3[0, :, :], cmap="gray")
axs[1, 1].set_title(f"Using DRUNet with n map={noise_level}", fontsize=16)
noaxis(axs[1, 0])
add_colorbar(im3, "bottom")
im4 = axs[1, 1].imshow(x_plot4[0, :, :], cmap="gray")
axs[1, 0].set_title(f"Using UNetRes with n map={noise_level}", fontsize=16)
noaxis(axs[1, 1])
add_colorbar(im4, "bottom")
plt.show()
Note
In this tutorial, we have used DRUNet with a DCNet but it can be used any other network, such as pinvNet. In addition, we have considered pretrained weights, leading to a plug-and-play strategy that does not require training. However, the DCNet-DRUNet network can be trained end-to-end to improve the reconstruction performance in a specific setting (where training is done for all noise levels at once). For more details, refer to the paper [ZhLZ21].
Note
We refer to spyrit-examples tutorials for a comparison of different solutions (pinvNet, DCNet and DRUNet) that can be run in colab.
References for DRUNet
Zhang, K.; Li, Y.; Zuo, W.; Zhang, L.; Van Gool, L.; Timofte, R..: Plug-and-Play Image Restoration with Deep Denoiser Prior. In: IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(10), 6360-6376, 2021.
Zhang, K.; Zuo, W.; Gu, S.; Zhang, L..: Learning Deep CNN Denoiser Prior for Image Restoration. In: IEEE Conference on Computer Vision and Pattern Recognition, 3929-3938, 2017.
Total running time of the script: (0 minutes 15.096 seconds)